|
Из-за несимметрии цены ошибки становится чрезвычайно трудно найти компромисс между ошибками 1-го и 2-го родов. Говоря иначе, трудно ответить на вопрос которая из двух моделей лучше: та, которая правильно идентифицирует 90% банкротств и на одну правильную классификацию дает 10 ошибок 2-ю рода, или та, которая идентифицирует 80% банкротств, но дает только 8 ошибок 2-го рода на одну классификацию.
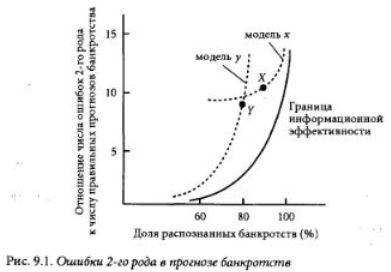
Как можно видеть из рис. 9.1, точки X и Y, показывающие качество прогнозов, соответственно, для моделей х и у, не дают возможности однозначно сказать, какая модель лучше. Если снизить требования к точности прогнозирования банкротства, то может оказаться, что модель х, по-прежнему, будет давать большее число ошибок 2-го рода и, тем самым, будет уступать модели у в таких приложениях, где ошибки 2-го рода относительно дороги по отношению к ошибкам 1-го рода.
Из сказанного следует, что качество модели прогнозирования банкротств можно оценить только при условии, что заранее заданы цена ошибок и вероятность банкротства/выживания. Если, например, нам известно, что цена одного не предсказанного вовремя банкротства равна цене пяти ложных треки1, и что потерпит банкротство один процент компаний, то мы можем оценить модели:
Цена ошибки модели х: 1% х [5 х (10%) + 10 х (1 - 10%)] - 0.095,
Цена ошибки модели у: 1% x [5 x (20%) + 8 х (1 - 20%)] = 0.074.
Модель х уступает модели у, которая пропускает 20% банкротов, но имеет более низкий показатель ошибок 2-го рода.
Если же одно пропущенное банкротство стоит 30 ложных тревог, то ошибки этих двух моделей будут такими:
Цена ошибки модели х: 1% x [30 х (10%) + 10 х (1 - 10%)] = 0.120.
Цена ошибки модели у: 1% x [30 х (20%) + 8 x (1 - 10%)] = 0.132, и модель х оказывается лучше, чем у. Заметьте, что наибольший вклад в погрешность модели вносит большое количество ошибок 2-го рода, и так получается потому, что они совершаются на жизнеспособных компаниях, а таких — подавляющее большинство. Решить, достаточно ли существенно отличаются результаты обеих моделей, чтобы по ним можно было высказывать предпочтение, здесь довольно трудно, так как неизвестно, как модель х будет работать при каком-либо совсем другом соотношении между пенами ошибок. При сдаче экзаменов на аудитора экзаменующиеся распознают только 25% компаний-банкротов, но зато на каждый правильный прогноз приходится только 4 ложных тревоги.
При том, что MDA-модели способны распознавать гораздо большую долю компаний-банкротов, общий результат не обязательно будет лучше, чем практика аудиторов. Так. если цена одной ошибки 1-го рода в 5 раз больше, чем ошибки 2-го рода, то итоговая погрешность аудиторов будет равна
1% х [5 х (75%) + 4 х (1 -75%)] = 0.0475, что меньше, чем у обеих гипотетических моделей х и у.
Эти примеры иллюстрируют следующую мысль: если соотношения пен ошибок различаются сильно, то настройка модели банкротств на конкретные пропорции, по-видимому, более важна, чем качество модели как таковое. Можно ввести обобщенное понятие информационной значимости модели, используя расстояние до так называемой эффективной информационной границы, т.е. кривой, огибающей результаты всех моделей. На рис. 9.1 модель х расположена ближе к этой границе, чем модель у, и поэтому ее следует считать более информационно эффективной.
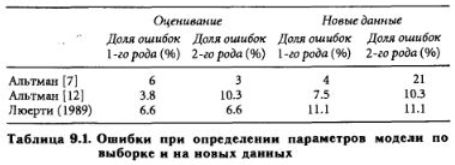
Следующая проблема — это выработка стандарта для тестирования. Для оценки MDA-моделей в большинстве случаев берется небольшое количество образцов, и это увеличивает вероятность того, что модель будет слишком точно подогнана под тестовые данные. В выборках обычно содержится поровну компаний-банкротов и небанкротов, а сами данные, как правило, соответствуют периодам интенсивных банкротств. Это приводит к выводу о том, что надежными являются только результаты оценки модели на новых данных. Из табл. 9.1 видно, что даже на самых благоприятных тестах с новыми данными (когда все примеры берутся из одного периода времени и притом однородными в смысле отраслей и размера предприятия) качество получается хуже, чем на образцах, по которым определялись параметры модели. Поскольку на практике пользователи моделей классификации не смогут настраивать модель на другие априорные вероятности банкротства, размер фирмы или отрасль, реальное качество модели может оказаться еще хуже. Качество может также ухудшиться из-за того, что в выборках, используемых для тестирования MDA-моделей, бывает мало фирм, которые не обанкротились, но находятся в зоне риска.

Если таких "с риском выживающих" фирм всего четыре-пять, то это искажает реальную долю рисковых компаний, и в результате частота ошибок 2-го рода оказывается недооцененной.
|



. В начале 2016 года был проведен ребрендинг и перевод обслуживания частных клиентов в международную компанию «NPBFX Limited» с лицензией IFSC. В банке продолжается обслуживание корпоративных клиентов.")

