|
Целью процедуры минимизации является отыскание глобального минимума — достижение его называется сходимостью процесса обучения. Поскольку невязка зависит от весов нелинейно, получить решение в аналитической форме невозможно, и поиск глобального минимума осуществляется посредством итерационного процесса — так называемого обучающего алгоритма, который исследует поверхность невязки и стремится обнаружить на ней точку глобального минимума. Иногда такой алгоритм сравнивают с кенгуру, который хочет попасть на вершину Эвереста, прыгая случайным образом в разные стороны. Разработано уже более сотни разных обучающих алгоритмов, отличающихся друг от друга стратегией оптимизации и критерием ошибок.
Коль скоро обучение основывается на минимизации значения некоторой функции (показывающей, насколько результат, который выдает сеть на данном обучающем множестве, далек от образцового значения), нужно, прежде всего, выбрать меру ошибки, соответствующую сути задачи. Удачный выбор меры погрешности обычно приводит к более гладкой поверхности невязки и упрощает задачу обучения. Обычно в качестве меры погрешности берется средняя квадратичная ошибка (MSE), которая определяется как сумма квадратов разностей между желаемой величиной выхода dt и реально подученными на сети значениями у, для каждого примера к:
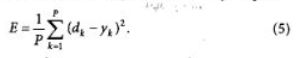
Здесь Р — число примеров в обучающем множестве.
Наряду с такой мерой погрешности широко используется рас
стояние Кульбака-Лейблера, связанное с критерием максимума правдоподобия.
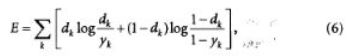
а также некоторые другие.
Минимизация величины Е осуществляется с помощью градиентых методов. В первом из них берется градиент общей ошибки, и веса W пересчитываются каждый раз после обработки всей совокупно
сти обучающих примеров («эпохи»). Изменение весов происходит в
направлении, обратном к направлению наибольшей крутизны для
функции стоимости:
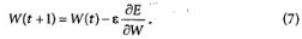
Здесь с — определяемый пользователем параметр, который называется величиной градиентного шага или коэффициентом обучения.
Другой возможный метол носит название стохастического градиентного. В нем веса пересчитываются после каждого просчета всех примеров из одного обучающего множества, и при этом используется частичная функция стоимости, соответствующая этому, например, k-му, множеству:

|



. В начале 2016 года был проведен ребрендинг и перевод обслуживания частных клиентов в международную компанию «NPBFX Limited» с лицензией IFSC. В банке продолжается обслуживание корпоративных клиентов.")
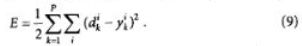
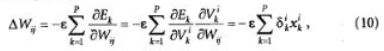
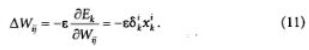
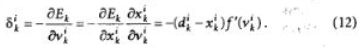
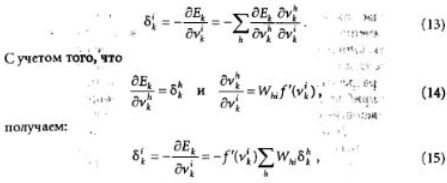

. Бесплатный демо-счет, депозит – от $10, опционы – от $1, торговля и вывод средств – без верификации.")
