|
Оба скрытых элемента и выходной элемент имели сигмоидную функцию преобразования с единичной крутизной и коэффициентом обучения 0.1. Полученные на выходе значения разбивались на три группы в соответствии с предполагаемым вариантом ответа на основной вопрос:

Здесь, как и в предыдущих случаях, мы применяли процедуру перекрестного подтверждения (по очереди отбрасывая каждое наблюдение) с цепью выбрать наилучшую конфигурацию сети (с точки зрения способности к обобщению) и получить оценку надежности модели. Каждый вариант конфигурации сети обучался в течение 30 циклов (3000 эпох) на 29 образцах, а 30-й образец оставлялся для проверки. Выбор подходящей архитектуры сети осуществлялся на основании статистики по среднеквадратичной ошибке (RMSE) перекрестного подтверждения (CV = Cross-Validation).

Была сделана попытка выбрать степень сложности модели, исходя из другого критерия — итоговой ошибки прогноза (FPE-Final Prediction Error). Эта величина вычисляется по ошибке на всем обучающем множестве с добавлением штрафного слагаемого за сложность модели:
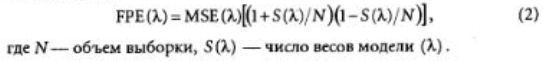
Для линейных моделей в предположении, что объем выборки достаточно велик, этот критерий дает несмещенную оценку риска обобщения при прогнозе. Это утверждение верно в асимптотическом смысле при N—>ас, и наши результаты указывают на то, что при S{\)-*N оно не выполняется. Утанс и Муди утверждают, что несмещенные оценки могут быть получены также для нелинейных моделей (в частности, нейронных сетей).
Мы подсчитывали FPE для различных сетей возрастающей сложности, и в табл. 8.11 приведены результаты, соответствующие двум видам выходных элементов: много порогового (0,0.5,1) и сигмоидного.
Для исследуемой задачи модель FPE1 (сигмоидная) представляется не вполне подходящей, так как FPE здесь более естественно было бы вычислять «ступенчато» (как это делается в FPE2). Критерий FPE2 имеет локальный минимум для конфигурации 3-1-1, что согласуется с результатами перекрестною подтверждения. Это, однако, говорит о том, что ни один из методов выбора модели не является идеальным (при конечном числе точек наблюдения). Поэтому мы остановим свой выбор на перекрестном подтверждении как на наиболее надежном методе выбора варианта модели и рассмотрим 3-1-1 сеть.
Из таблицы результатов классификации для 3-1-1 сети (см. табл. 8.13) видно, что 80% случаев из 1-й группы и 90% из 3-й группы были классифицированы правильно. С другой стороны, из сомнительных компаний ни одна не была идентифицирована правильно.
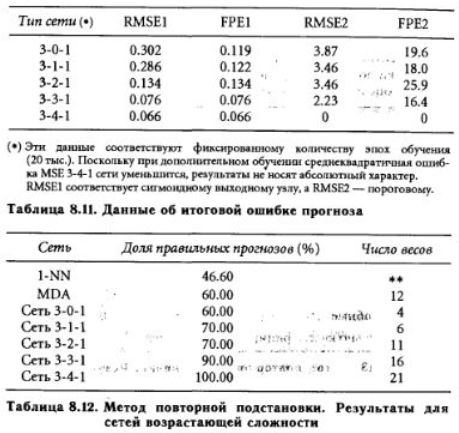
Мы проводили также обучение этих сетей на всем обучающем множестве (метод повторной подстановки), меняя при этом число скрытых элементов от 0 до 4. Как и следовало ожидать, при увеличении сложности сети (числа весов) ошибка классификации уменьшалась, а для сети с четырьмя скрытыми элементами даже было достигнуто полное соответствие в отображении (ошибка равна нулю). Так как для отделения друг от друга трех групп понадобилось 4 скрытых элемента, задача, очевидно, является нелинейно отделимой. Однако результаты перекрестного подтверждении заставляют сомневаться в возможностях такой сети к обобщению. Далее будут анализироваться результаты, полученные для модели 3-1-1 после 7000 эпох обучения.
Конфигурация 3-1-1 дает точность классификации примерно 70%, что на 10% лучше, чем MDA. В первой группе число правильно классифицированных элементов стало больше на 30% — прекрасный результат с учетом того, что структура базы данных позволяет анализировать только ошибки 1-го рода. Показательно, что и MDA, и нейронная сеть одновременно неправильно классифицировали одну из компаний 1-й группы (№13 в списке) как жизнесносо6ную (отнесли ее к 3-й группе). Такое совпадение заставило банк пересмотреть ее рейтинги. Оказалось, что эта компания получила очень высокие оценки по многим параметрам благодаря тому, что в тот момент качество опенки было несовершенным.

Нейронная сеть не смогла превзойти результаты метода MDA на 2-й группе компаний. Эта группа состоит из фирм с неясным будущим. В данный момент их финансовое положение неустойчиво, и, возможно, они справятся с этими трудностями, а, может быть, и нет. Было бы интересно сравнить результаты классификации с тем, что в действительности произошло с этими фирмами спустя некоторое время. Опять-таки, приятно отметить, что компании, неправильно классифицированные методом MDA, были также неправильно оценены нейронным классификатором. 100-процентный результат, достигнутый на 3-й группе, говорит о том, что эта часть компаний образует отчетливо выделяемую область в пространстве переменных.
Все полученные результаты собраны на рис. 8.1, где для каждой компании наряду с ее истинным номером группы (целевой переменной) изображены результаты ее классификации 3-1-1 нейронной сетью, методами MDA и 1-NN.

Для удобства дискретные выходные значения представлены в непрерывном виде.
|



. В начале 2016 года был проведен ребрендинг и перевод обслуживания частных клиентов в международную компанию «NPBFX Limited» с лицензией IFSC. В банке продолжается обслуживание корпоративных клиентов.")
. Бесплатный демо-счет, депозит – от $10, опционы – от $1, торговля и вывод средств – без верификации.")
